El comando file en Linux es una herramienta poderosa y versátil utilizada para determinar el tipo de un archivo. Al contrario de lo que podría parecer, file no se basa únicamente en la extensión del archivo, sino que analiza el contenido del mismo para identificar su tipo. En este post, exploraremos cómo funciona este comando, sus opciones más útiles y ejemplos prácticos de su uso.
El comando file examina el contenido de los archivos y devuelve una descripción de su tipo. Esta descripción puede indicar si el archivo es de texto, binario, una imagen, un ejecutable, entre otros. Para obtener esta información, file utiliza tres métodos principales:
La sintaxis básica del comando file es muy simple:
file [opciones] archivo
Donde “archivo” es el nombre del archivo que se desea analizar. A continuación, veremos algunas de las opciones más comunes y útiles.
Este comando incluye varias opciones que permiten personalizar su comportamiento. Algunas de las más útiles son:
-b, –brief: Muestra solo el tipo de archivo, sin el nombre del archivo.
file -b nombre_del_archivo-i, –mime: Muestra el tipo MIME del archivo, útil para identificar el tipo de contenido de manera más específica.
file -i nombre_del_archivo-f nombre_de_archivo, –files-from nombre_de_archivo: Lee una lista de archivos desde un archivo especificado.
file -f lista_de_archivos.txt-z, –uncompress: Examina el contenido de archivos comprimidos.
file -z archivo_comprimido.gzVamos a ver algunos ejemplos prácticos:
Supongamos que tenemos un directorio con un archivo de texto, si ejecutamos el comando file sobre este archivo, obtendremos el siguiente resultado:
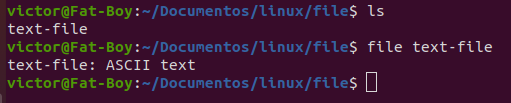
Como podemos ver, en este ejemplo ejecutamos primero el comando ls para listar los archivos en el directorio; posteriormente, el comando file nos devuelve el nombre del archivo seguido de su tipo, en este caso ASCII text.
Dentro de Linux no es obligatorio especificar una extensión para cada archivo, las “extensiones” que vemos en algunos nombres, el sistema operativo los considera como parte del mismo. Veamos un ejemplo práctico, supongamos que tenemos una imagen png en un directorio, pero no podemos identificar su tipo porque no hay extensión.
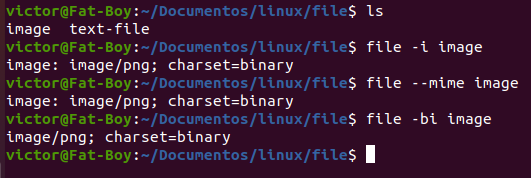
En este ejemplo identificamos el archivo image, por su nombre podemos suponer que es una imagen, pero en Linux no podemos estar seguros a simple vista. El comando file entra en juego, lo ejecutamos sobre el archivo con la opción -i o –mime y nos muestra que es una imagen png (image/png). En la última línea ejecutamos el comando combinando la opción mime y la opción brief, para mostrar solo el tipo sin el nombre.
Siguiendo con el ejemplo anterior, agregaremos un archivo de texto con una lista de los archivos ya existentes (text-file e image, uno en cada línea) y ejecutaremos file para leer estos dos archivos a la vez.
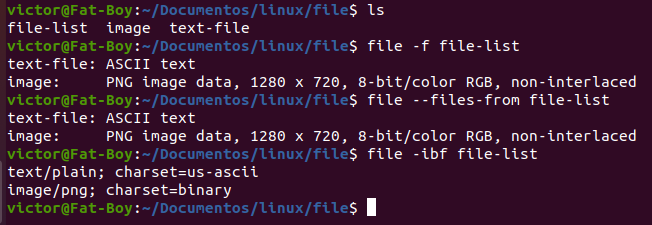
Como podemos ver ahora tenemos tres archivos, file-list contiene una lista con los otros dos. Si ejecutamos el comando file con la opción –files-from y esta lista como parámetro, nos muestra los nombres y tipos de los archivos en la lista. Incluso en la última línea combinamos dos opciones más.
Agreguemos ahora un archivo zip al directorio. Usaremos la opción –uncompress para obtener información sobre su tipo. Es pertinente aclarar que esta opción no descomprime el archivo, solo nos devuelve información acerca de su contenido.
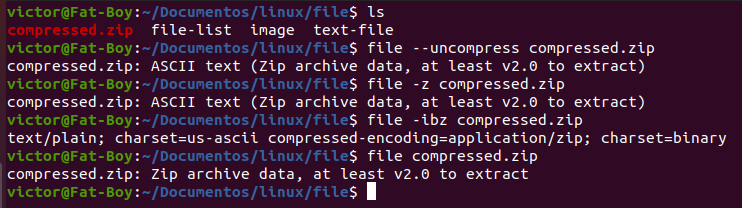
El comando file en Linux es una herramienta esencial para cualquier administrador de sistemas o desarrollador. Su capacidad para analizar y describir el contenido de los archivos, más allá de las extensiones, lo hace extremadamente útil en una amplia variedad de situaciones. Para más detalles sobre este comando, puedes consultar la página del manual.
Esperamos que esta guía te haya sido de ayuda y que ahora tengas una mejor comprensión de cómo usar el comando file en tus tareas diarias con Linux. Aprende también acerca de el comando cd en linux.